Health Insurance Cost Predictor🫰
Project Overview
Situation: The project aims to help insurance providers estimate medical insurance payouts by predicting health insurance costs for individuals.
The goal is was to develop a machine learning model that accurately forecasts "claim" amounts to optimize premium pricing and financial risk assessment.
Technologies Used:
- Python
- Pandas, NumPy - for Data Analysis
- Matplotlib, Seaborn - Visualization
- Scikit-learn - Machine learning
- Streamlit, Joblib - Visualization and Model Serialization
My steps:
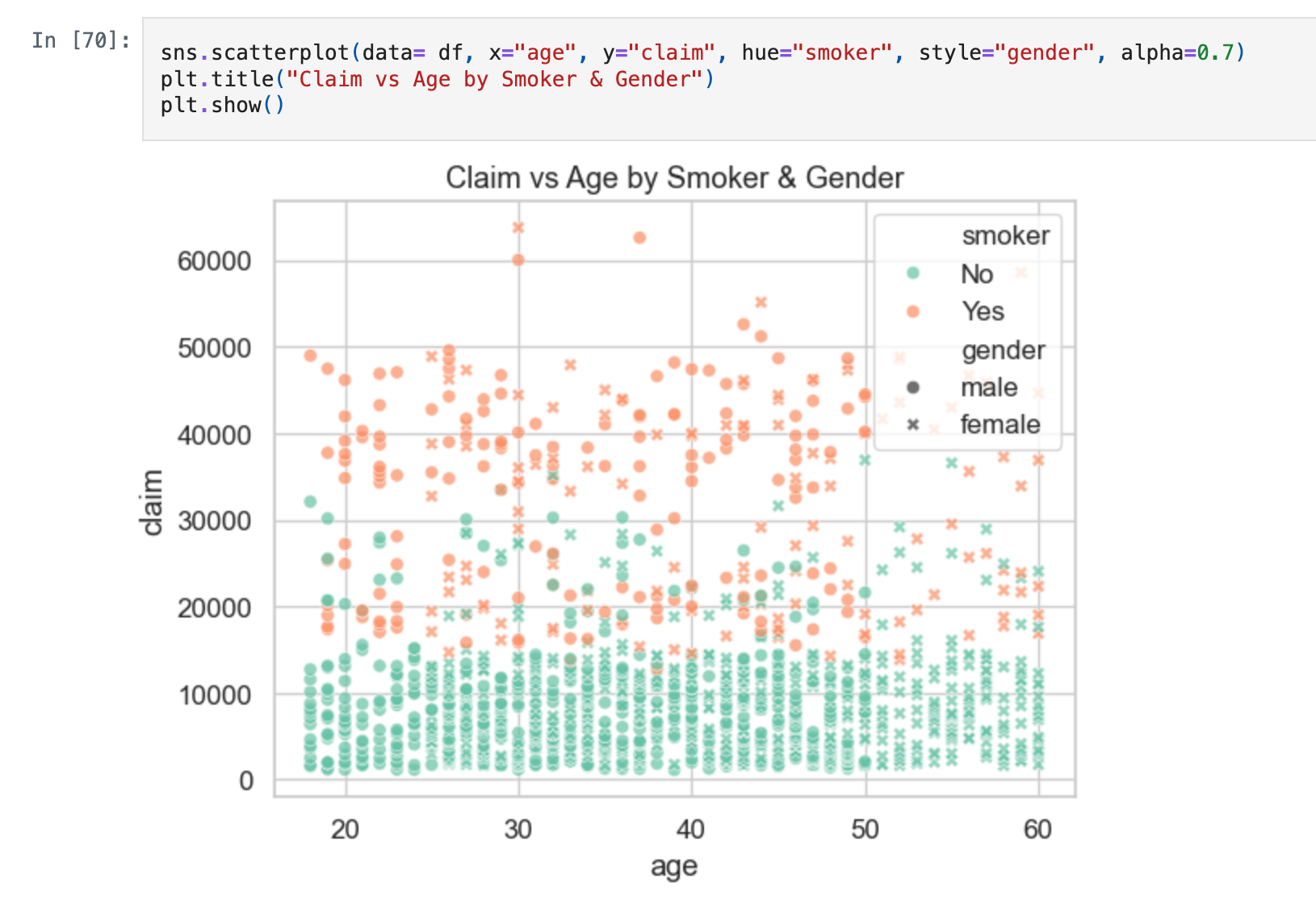
- 1. Exploratory Data Analysis (EDA): Analyzed feature distributions and correlations, discovered that smoking status and BMI were the strongest predictors of high claim amounts
- 2. Feature Engineering: Created categorical bands for age and BMI (e.g., underweight, obese) to better capture non-linear relationships
- 3. Data Preprocessing: Handled missing values, applied Label Encoding for categorical variables, and used StandardScaler for feature scaling
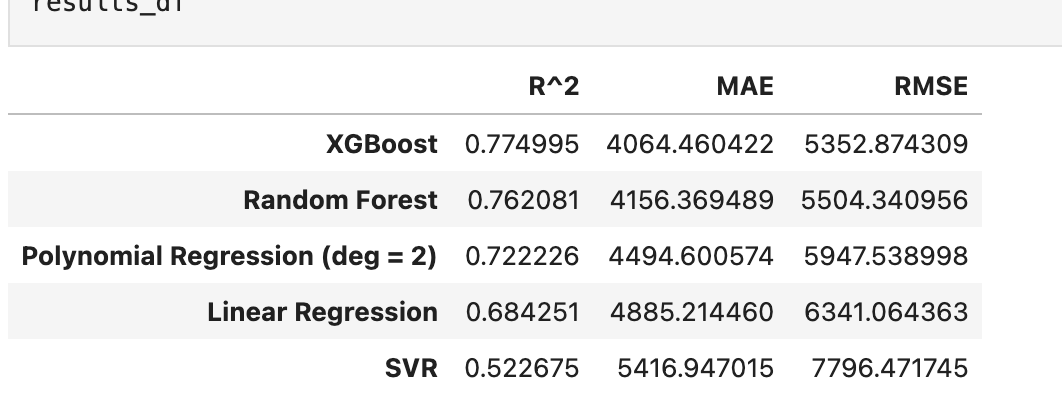
- 4. Model Training & Optimization: Evaluated five regression models (Linear, Polynomial, Random Forest, SVR, and XGBoost) using Grid Search for hyperparameter tuning.
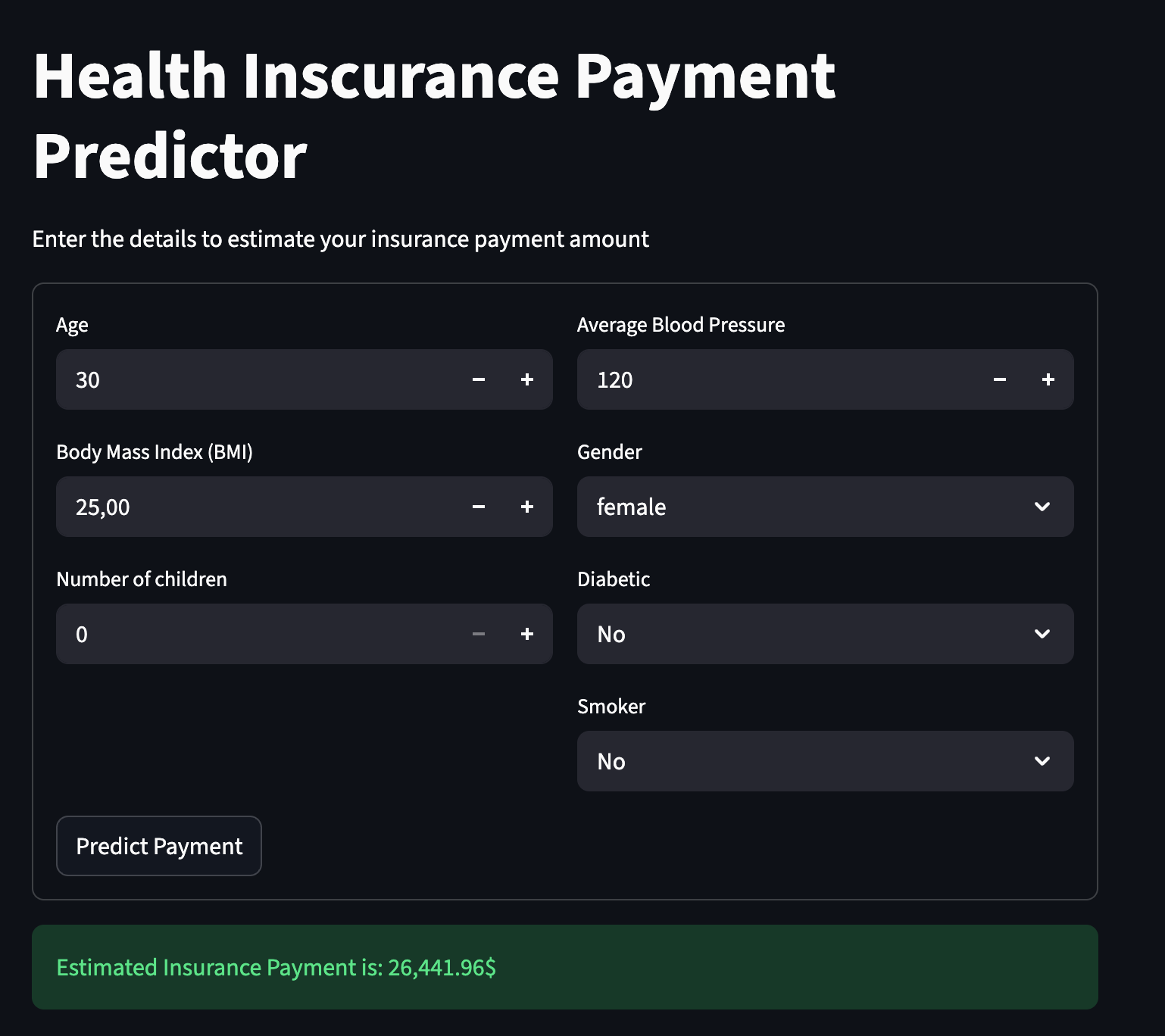
- 5. Deployment: Developed an interactive Streamlit web application that allows users to input their health data and receive real-time insurance cost estimates
Results:
- Best Model: XGBoost outperformed other models, achieving around 78% precision score.
- Outcome: Built a scalable end-to-end pipeline that automates the transition from raw data to a user-friendly prediction tool.