ETL Pipeline ⚙
Project Overview
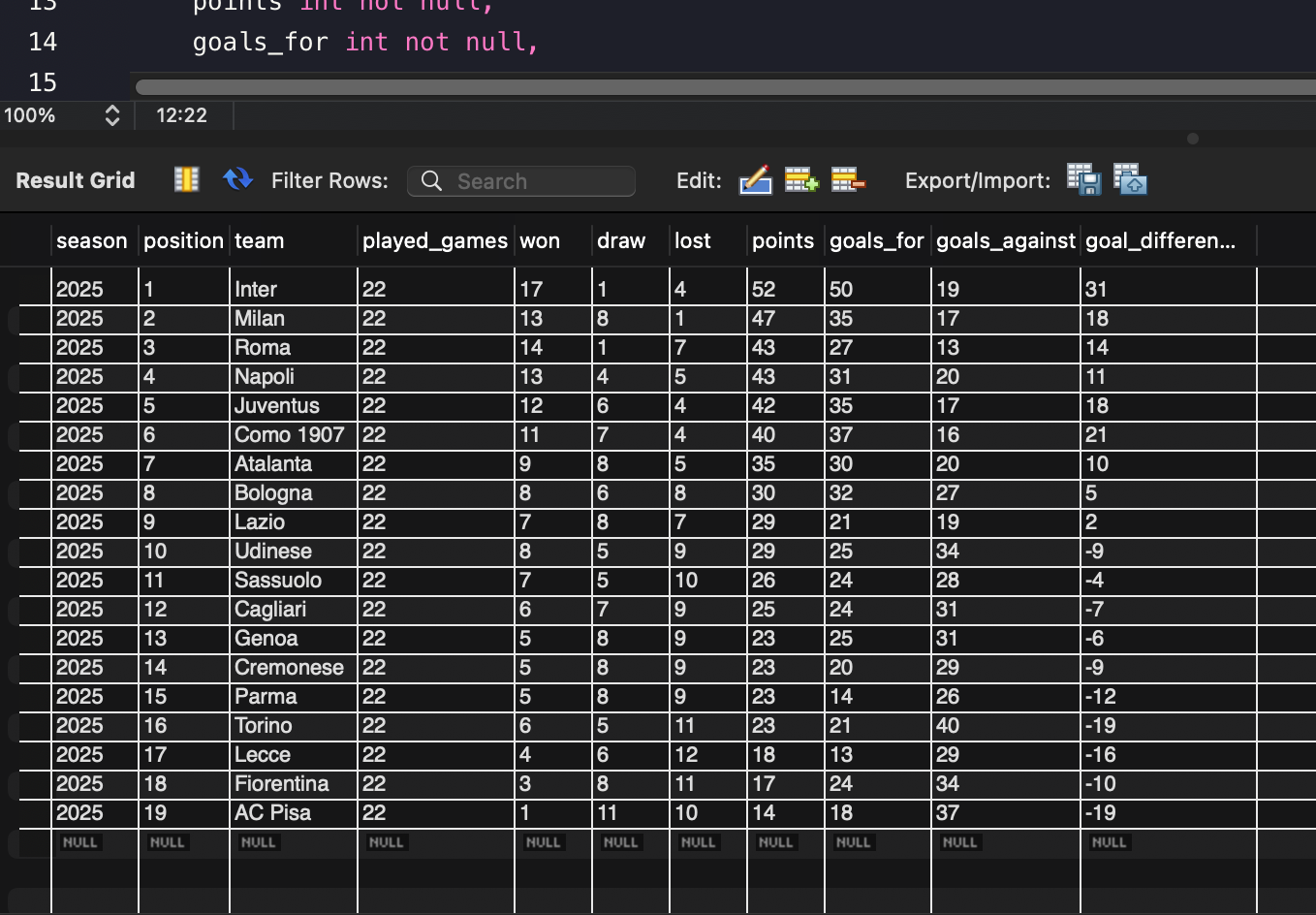
This project is an application that extracts real-time football standings (specifically for Serie A), processes the raw data, and loads it into a relational database. It is designed as an ETL (Extract, Transform, Load) pipeline using an "Upsert" operation, allowing the database to be updated daily without creating duplicate entries.
Technologies Used:
- Python
- MySQL/SQL
- Jupyter Notebooks
- APIs
My steps:
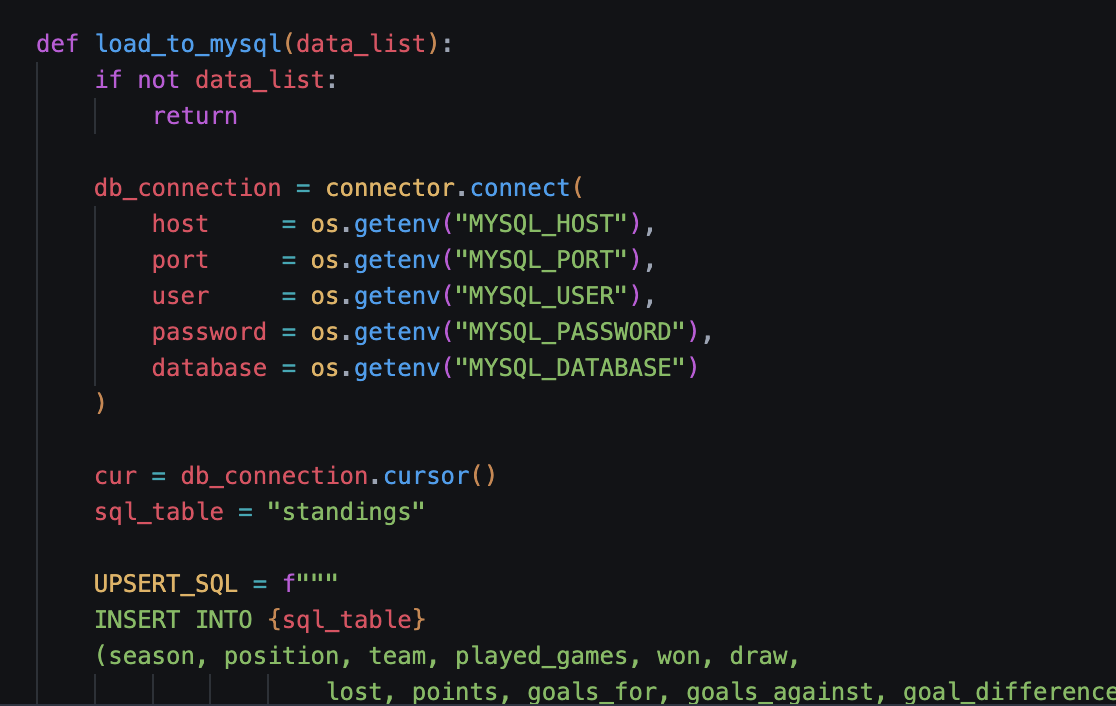
- 1. Environment Setup: The script begins by loading an .env file to securely retrieve the API_KEY, MYSQL_HOST, and MYSQL_PASSWORD. This prevents hard-coding sensitive information into the script.
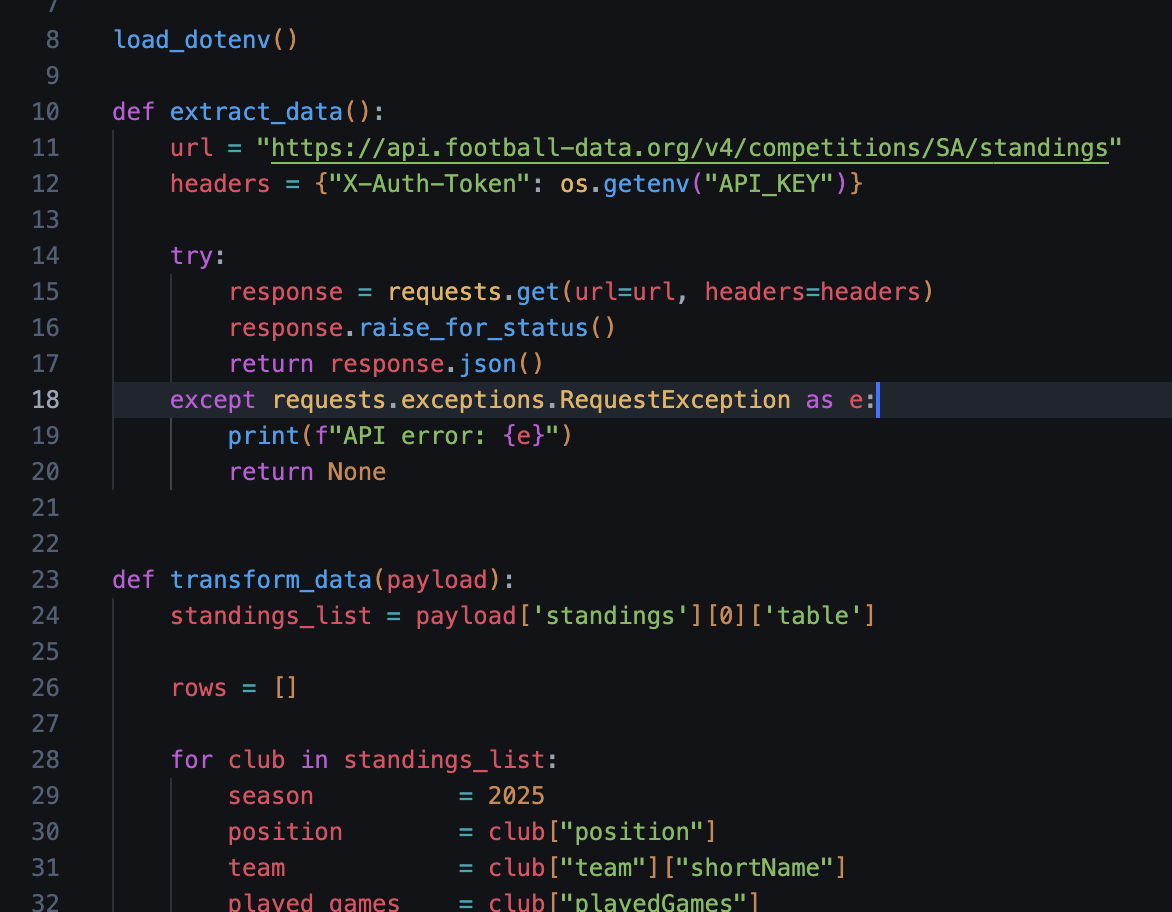
- 2. Extraction (Extract) The script connects to the football-data.org API using a GET request with authentication headers. It specifically targets the Serie A competition standings and retrieves the response in JSON format.
- 3. Transformation (Transform) The raw JSON data is parsed to isolate the standings table. The script iterates through the list of teams and extracts 11 specific data points for each club
- 4. Loading (Load) The script opens a connection to the MySQL database and executes a bulk insertion.
- Replaced manual data entry with a script that can fetch the latest stats in seconds.
- The script can be run 100 times a day without breaking the database or creating duplicate rows for the same team.
- The logic is modular (using functions in main.py), meaning it can easily be adapted to fetch data for other leagues like the Premier League or La Liga just by changing the URL.